Почему вашего сайта нет в ответах ChatGPT и Perplexity
Как попасть в ответы нейросетей: почему обычного SEO уже недостаточно
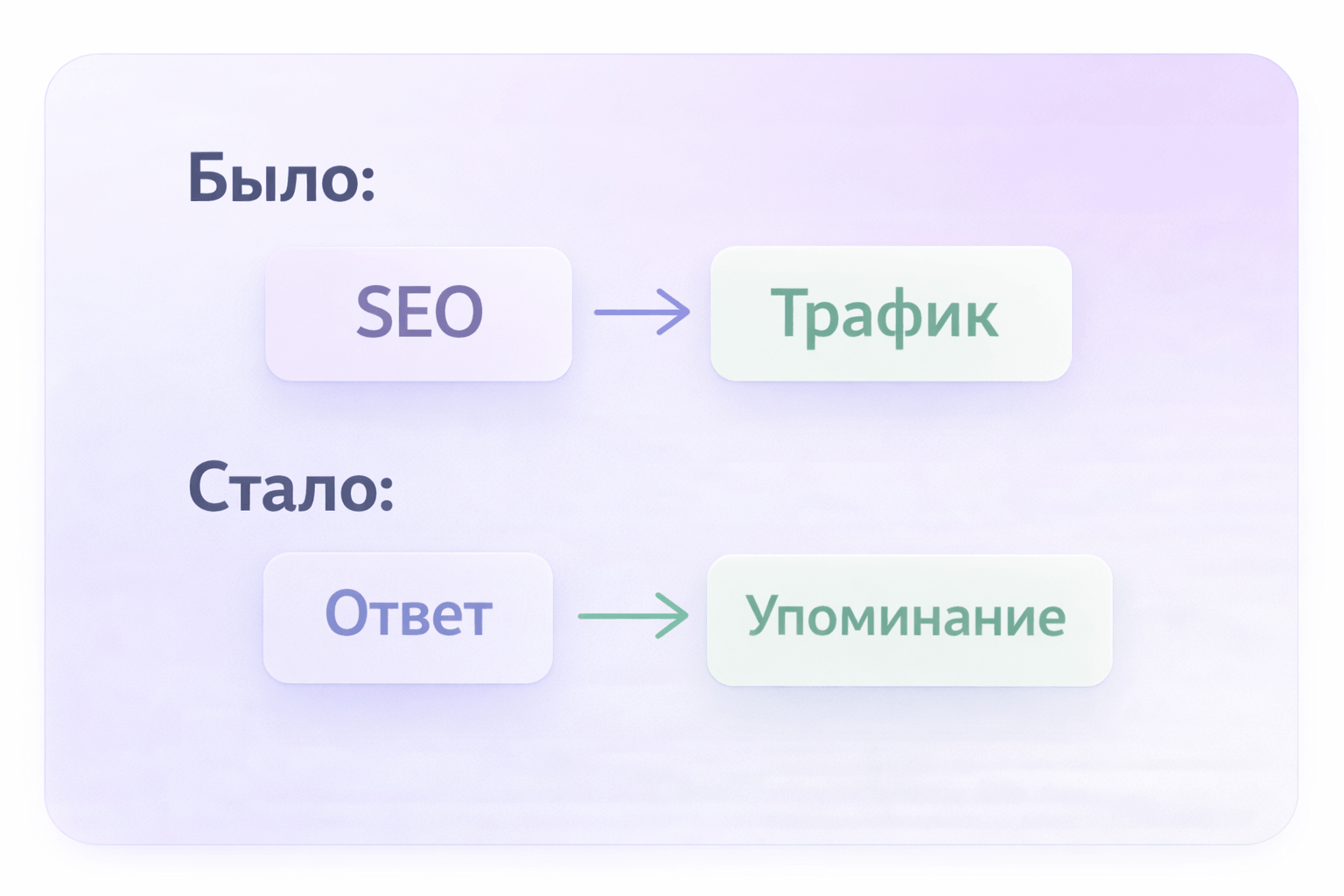
Сейчас важно учитывать, что сами способы поиска меняются. Пользователи всё чаще идут не в Google, а сразу задают вопрос в ChatGPT или Perplexity AI и получают готовое объяснение. В этом сценарии они могут вообще не переходить на сайты — если ответ их устраивает.
И в этот момент сайт перестаёт быть точкой входа — он становится источником внутри ответа.
Проблема становится заметной не сразу. Сайт работает, трафик есть, всё выглядит нормально — пока не выясняется, что в ответах нейросетей его просто нет. Запрос есть, объяснение есть, но без вашего материала.
И тут быстро становится понятно: важна уже не позиция, а то, используют ли ваш текст.
Раньше схема была прямолинейной: пользователь открывал поиск, переходил по сайтам, сравнивал. Теперь всё чаще он получает готовый ответ сразу. И если ваш материал не подходит для такого формата — его просто не используют. Даже если он «в топе».
Чтобы понять, как туда попасть, сначала важно разобраться, как нейросети вообще выбирают источники.
Как нейросети выбирают тексты для ответа
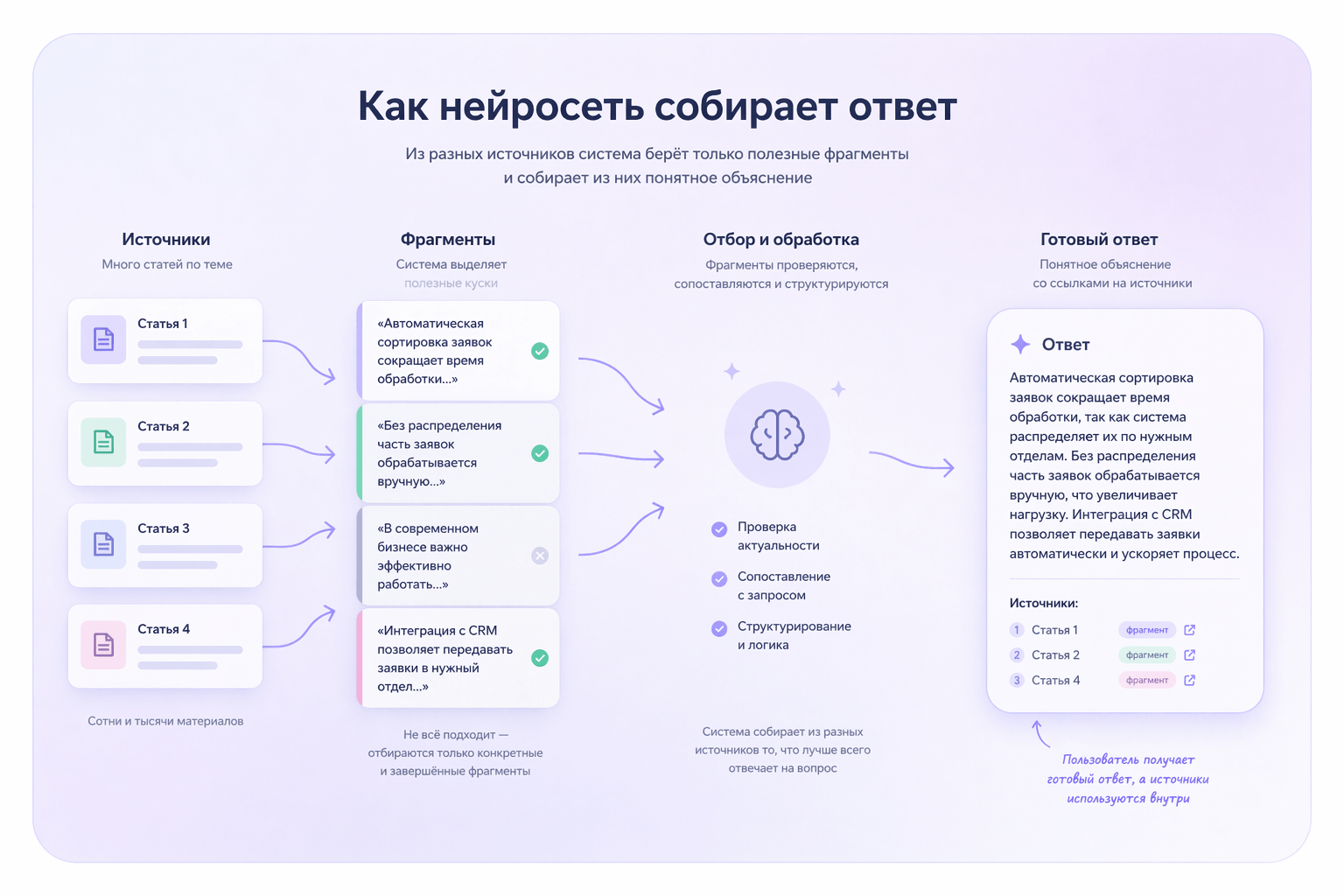
Нейросети не ранжируют сайты в привычном смысле. Они собирают ответ из уже существующих материалов. И ключевой критерий здесь — не «позиция страницы», а «пригодность текста к использованию».
На практике это выглядит так: система ищет фрагменты, которые можно взять и вставить почти без изменений. Если абзац чётко отвечает на один вопрос — он подходит. Если мысль размазана или требует дополнительного контекста — его пропускают.
Здесь и возникает первый конфликт. Сайт может занимать хорошие позиции в поиске, но не попадать в ответы. И наоборот — небольшой, но точный текст может использоваться регулярно, даже без сильного SEO.То есть выигрывает не тот, кто выше, а тот, кого проще использовать.
Причём важна не только точность, но и завершённость. Абзац должен быть самодостаточным: прочитал — понял — можно использовать. Если без соседних частей смысл теряется, такой кусок почти не имеет шансов.
По разным разборам LLM-поиска, именно такие «завершённые» фрагменты чаще всего используются в ответах (например, это хорошо видно на практике в Perplexity AI).
Почему классическое SEO уже не даёт нужного результата
Классический подход всё ещё работает, но уже не в чистом виде. Ключевые слова сами по себе ничего не гарантируют. Длинные тексты с «правильными формулировками» могут приводить трафик, но не использоваться нейросетями.
Чаще всего проблема в том, что такие статьи пишутся под поиск, а не под объяснение. В них много вводных фраз, обобщений и попыток «раскрыть тему полностью». В итоге внутри нет чётких ответов, которые можно взять отдельно.
Парадокс в том, что короткий текст иногда заходит лучше длинного. Не потому что он проще, а потому что из него легче вытащить конкретный смысл. Когда написано прямо — например, что время обработки заявок сокращается за счёт автоматической сортировки — это можно сразу использовать. А общие формулировки вроде «повышает эффективность бизнес-процессов» вроде звучат нормально, но по факту ничего не объясняют.Красиво — не значит полезно. В этом и ломается большинство текстов.
На этом этапе обычно и возникает проблема. Текст вроде есть, тема раскрыта, но в ответах нейросетей его нет. Значит, дело уже не в SEO, а в том, как устроен сам материал.
Как писать тексты, которые попадают в ответы нейросетей
Тексты, которые регулярно используются в ответах, почти всегда устроены одинаково. Они пишутся не «про тему», а под конкретные вопросы. И каждый абзац в них можно использовать как отдельный ответ.
Часто решает не общий уровень текста, а то, можно ли из него взять готовый ответ. Нейросети не переписывают материал с нуля — они ищут формулировки, которые уже звучат как объяснение. Если абзац прямо отвечает на вопрос, его проще использовать.Фактически ты пишешь не статью, а набор готовых ответов.
Например, не просто описывать тему, а формулировать: «основная причина в том, что…», «чаще всего это происходит из-за…», «чтобы это работало, нужно…». В таком виде текст превращается в набор фрагментов, которые можно вставить почти без изменений.
Если посмотреть на практику внедрения таких подходов в проектах, мы в Alien Source как раз используем похожую логику при работе с контентом и приложениями — когда структура сразу строится под извлечение смысла, а не просто под чтение.
При этом важно не уйти в крайности. Попытка «писать красиво» часто ухудшает результат: появляются сложные конструкции, смысл размазывается. Но и чрезмерное упрощение не работает — текст становится поверхностным.
Обычно помогает базовый набор действий. Сначала текст разбивается на вопросы: что именно пользователь хочет понять. Затем под каждый вопрос пишется короткий и законченный ответ. Внутри — конкретика: ситуации, этапы, ограничения.
Например, если входящих заявок около 300 в день и они приходят из разных каналов, без автоматической сортировки часть из них всё равно обрабатывается вручную. Это сразу показывает, где возникает нагрузка и почему она не исчезает полностью.
При этом важно добавлять ограничения. Не «решает проблему», а «снижает нагрузку, но часть случаев остаётся на ручной проверке».Именно такие детали делают текст живым и пригодным для использования.

Где чаще всего ломаются статьи
Даже при нормальной структуре многие тексты не попадают в ответы. Обычно причина — в типичных ошибках.
Первая — текст пишется «для SEO». В нём много правильных слов, но нет конкретных объяснений. Кажется, что статья полезная, но взять из неё нечего.
Вторая — отсутствие структуры. Сплошной текст без чётких блоков сложно разрезать на части. В итоге он не используется.
Третья — слишком общий уровень. Например, описывается работа с заявками, но без указания, где именно возникает задержка: на этапе проверки, передачи или согласования.А в реальности именно такие места и решают всё.
Четвёртая — идеальность. Всё «работает», «оптимизирует», «повышает». Без оговорок и ограничений. Такой текст выглядит аккуратно, но не отражает реальный процесс.
В результате получается странная ситуация: статья написана правильно, но нейросеть не может взять из неё ни одного готового ответа.
Что делать, чтобы начать попадать в ответы
Если собрать всё вместе, логика довольно простая. Текст должен закрывать конкретные вопросы, а не просто «рассказывать про тему». Лучше, когда каждый абзац сам по себе что-то объясняет и его можно использовать отдельно.
Внутри — не общие слова, а нормальная конкретика: ситуации, цифры, этапы. Обязательно добавлять ограничения: где не работает полностью, где остаётся ручная проверка, где возникает компромисс.
Также важно убирать воду. Любая фраза, которая не даёт понимания или действия, мешает. Если абзац можно удалить без потери смысла — его лучше убрать.
В практических проектах это обычно означает пересборку контента: не переписывание «красиво», а разбиение на рабочие смысловые блоки.
Полностью контролировать попадание нельзя. Но можно сильно повысить шанс, что текст вообще начнут использовать.
Итог: как меняется логика работы с контентом
Нейросети не ищут сайты — они собирают ответы. И выигрывает не тот, у кого больше текста или лучше оптимизация, а тот, чьи материалы проще использовать.
Это не отменяет SEO, но добавляет новый слой. Теперь важно не только привести пользователя, но и стать частью ответа, который он получает.
И именно под эту задачу сейчас всё чаще приходится перестраивать контент и структуру продуктов — в том числе на практике в Alien Source, где мы сразу учитываем, как материалы будут использоваться внутри ответов нейросетей.
Если коротко: если текст нельзя вырезать и вставить как готовое объяснение — он почти не имеет шансов попасть в нейросеть.И сейчас это важнее, чем просто быть в топе поиска.